* Front page
* Overview
Requirements
* Install
* Screenshots
* Documentation
FAQ
User guide
Related links
API
* License
* Download
* Evaluation
Mustru: Install
Linux
- Unzip the distribution to the installation directory.
- Set the MUSTRU_HOME environment variable to the installation directory
- Set the CATALINA_OPTS environment variable to
export CATALINA_OPTS="$CATALINA_OPTS -DMUSTRU_HOME=$MUSTRU_HOME" - Set the JAVA_HOME to the JDK directory or JRE_HOME to the JRE directory (optional if one of the vars exists)
- Add MUSTRU_HOME/bin to your PATH environment variable
- Run runOnlineIndex.sh from the bin directory and run Load Tables from the Test menu.
- Copy the mustru.war file in the lib directory to your Tomcat webapps directory.
Windows
- Run the setup.exe file to copy files to the specified installation directory and set environment vars.
- Set the JAVA_HOME to the JDK directory or JRE_HOME to the JRE directory (optional if one of the vars exists)
- Run runOnlineIndex.sh from the Start menu under Mustru Services to create an index and run Load Tables from the Test menu.
- Copy the mustru.war file in the lib directory to your Tomcat webapps directory.
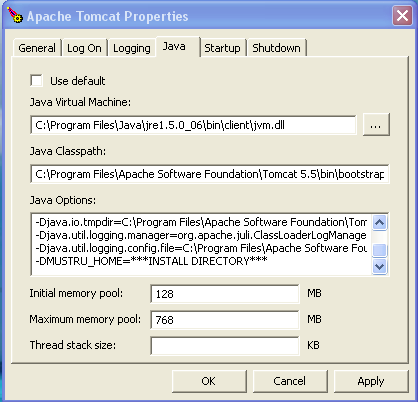
- Tomat configuration: You can use the GUI shown below to
configure Mustru and increase heap allocation or set the
environment variable MUSTRU_HOME in the startup.bat file and
JAVA_OPTS in catalina.bat.
Using Mustru
-
Build an index - run runOnlineIndex.sh to create / modify
an index, options include
- A fresh crawl (will create a new index) or an incremental crawl
- Duplicates (files the same content) can be skipped
- Hidden files (files starting with a '.') can be skipped
- Number of threads to create an index (use more than 1 on a multi-processor machine)
- A list of directories that will be scanned for indexable files
- A list of directories that should not be included in the index
- Extract entities (needed for Q&A function alone)
- Location of the directory that will contain the Lucene index
- Location of the directory that will contain the Berkeley DB
- Optional root directory of the local Web server (needed to generate URLs with the localhost in a list of hits)
- Search the index from a browser - start the following URL http://localhost:8080/mustru
Troubleshooting
- Tomcat startup error: Tomcat may not start for several reasons. Check the RUNNING.txt file in the main directory for errors. Also check if your firewall is blocking connections.
- OutofMemory error: Tomcat starts with an initial heap size which may not be sufficient for Mustru. To increase the heap size, add the following line in the beginning of your bin/catatlina.(sh/bat) file
set JAVA_OPTS="-Xmx768M -Xms64M" or use the environment variable set CATALINA_OPTS="%CATALINA_OPTS% -Xmx768M -Xms64M" - Could not create DB environment (JE 3.1.0) The Environment directory ... : The Berkeley database directory maybe read only or may not exist. Check for permissions to write to the database.
Copyright © 2007 Mustru Search Services. All rights reserved.