* Front page
* Overview
Requirements
* Install
* Screenshots
* Documentation
FAQ
User guide
Related links
API
* License
* Download
* Evaluation
Mustru: Overview
Mustru offers desktop search functions as well as an experimental Q&A feature. Some of the features include -
- Extracts text from common file types including HTML, PDF, and DOC (over 40 suffixes handled).
- Includes checks for duplicate content.
- Uses GATE to find entities (people, places, and organizations) in text.
- Multi-threaded indexing, categorization, and entity extraction.
- Runs indexing offline (shell script) or online (using a GUI)
- Auto-recovery of an aborted index operation
- Repairs the index by verifying that all files mentioned in the index exist in the filesystem (fixes dead links).
- Finds similar documents for a particular hit.
- Expands queries to find more hits
- Accepts questions in natural language and returns a list of passages (answers)
- Categorizes files into web pages, articles, letters, books, or media files
- Uses the names of multimedia files in the index
- Categorizes the text content into business, sports, or health (using a pre-defined taxonomy)
- Based on open source tools including - Lucene, Wordnet, Lingpipe, GATE, and Berkeley DB.
- Search from a Web based interface (JSP/Servlet running on Tomcat)
Creating an Index
Run the online index script to generate the following GUI and create a new crawl. In the new crawl, select directories to include or exclude from the crawl.

You can specify the filesystem directories for the index and database. If you are going to index a large collection, you may need to increase the heap size in the script. Options include the extraction of entities (needed for Q&A) and incremental crawl . The initial crawl is a fresh crawl and the following periodic crawls are incremental crawls.
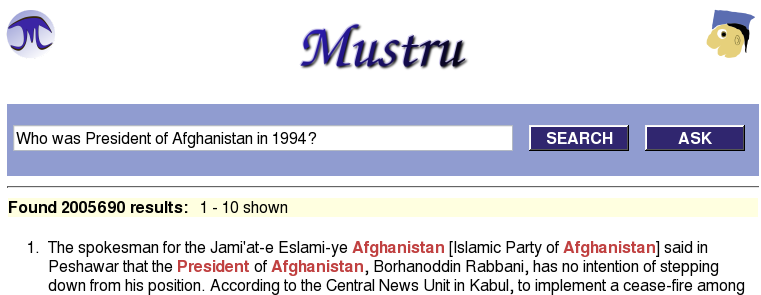
Searching an Index
Search the index using a Web based interface with the Mustru webapp. Install the mustru.war file in your Servlet container and run queries or questions.
Requirements
Mustru runs on Linux and Windows. It is written in Java and uses several jar files that have been included in the distribution. Your memory requirements will depend on the size of the document collection. Indexing a large collection with a small heap will generate 'Out of Memory' errors. You will need at least 256 M to use the Q&A functions. If you have less memory, you can run the search engine function alone (without extracting entities during the crawl).
- Java Run Time (JRE) Java 2 Version 5.0
- (Optional) Java Development Kit (JDK) Java 2 Version 5.0 to compile the source
- A Servlet container -- Mustru has been tested on Tomcat 5.5
Copyright © 2007 Mustru Search Services. All rights reserved.